Unlock Hidden Patterns: The Simple Yet Powerful Solution to Finding Longest Common Substrings
Unlock Hidden Patterns: The Simple Yet Powerful Solution to Finding Longest Common Substrings
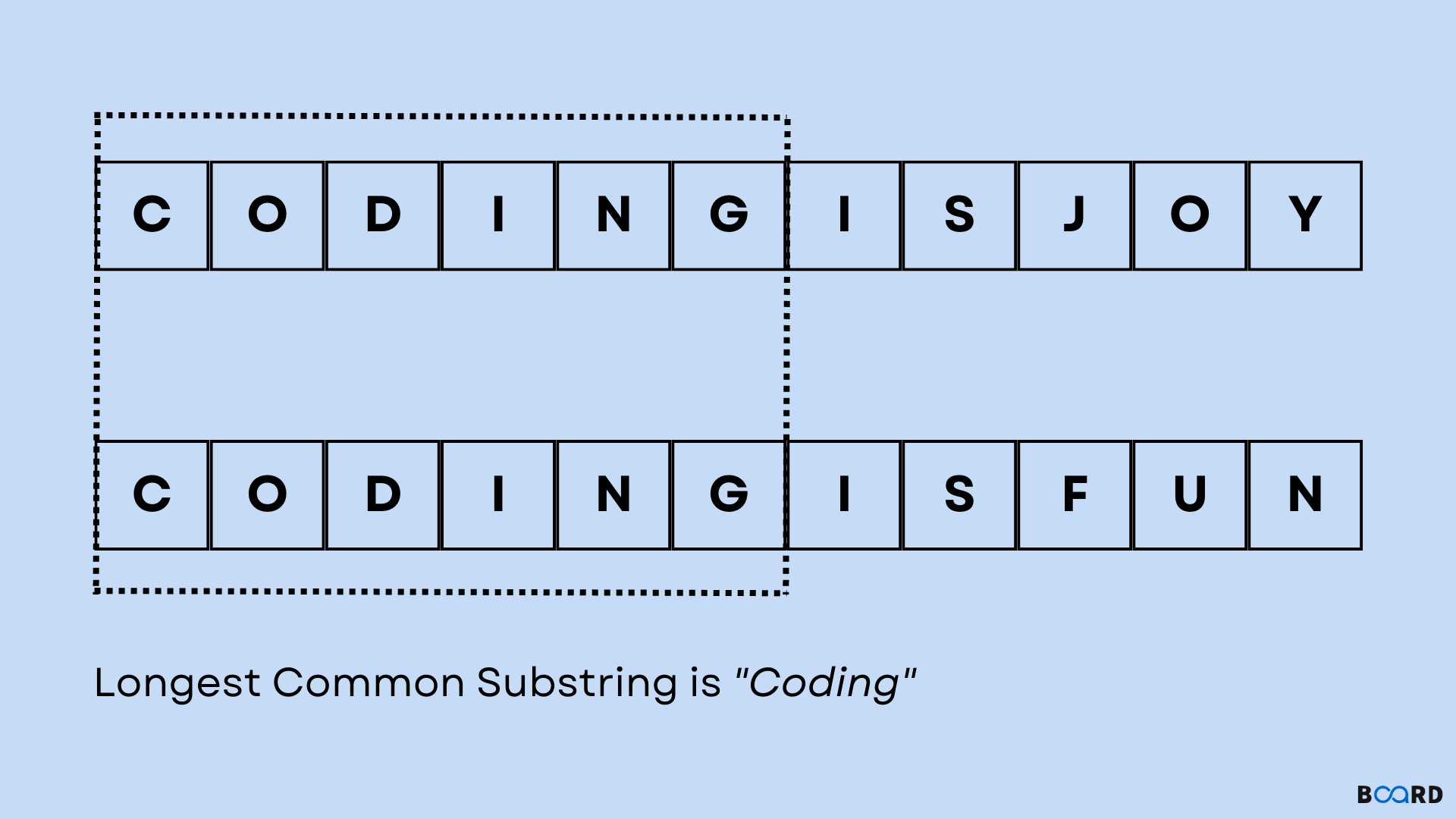
In a world driven by data, the ability to detect similarities across strings—document snippets, DNA sequences, user inputs, or even copyrighted text—hinges on a foundational algorithmic challenge: identifying the longest common substring. Despite its technical roots, the core concept remains remarkably accessible. By leveraging efficient preprocessing and smart comparison, analyzing textual relationships no longer demands complex programming or heavy computational resources.
This breakthrough solution transforms an otherwise daunting problem into a practically executable task, empowering researchers, developers, and analysts alike. The challenge of finding the longest common substring—defined as the maximum-length contiguous sequence present in two input strings—has long attracted attention in computer science. Traditional approaches, such as


Related Post

Unlocking the Secrets of Sleep: How the Science of Rest Powers Health and Performance

Quarter to Seven: The Precision Switch That Transforms Lives, One Quarter at a Time

The Unbanned Phenomenon: Unlocking Freedom in the Digital Age

Tim Matheson’s Private Life: Wife Elizabeth Marighetto, Age, and the Quiet Strength Behind the Actor’s Legacy



